
A new AI video model appeared overnight with no team name, no launch post, and no paper. It beat Seedance 2.0 by 74 Elo points on the most credible blind-preference leaderboard in the industry. As of May 13, 2026, HappyHorse production pricing has also become more aggressive: 720p generation dropped from $0.18/s to $0.128/s, and 1080p dropped from $0.30/s to $0.229/s.
Nobody knew who built it. The AI community spent 48 hours trying to find out.
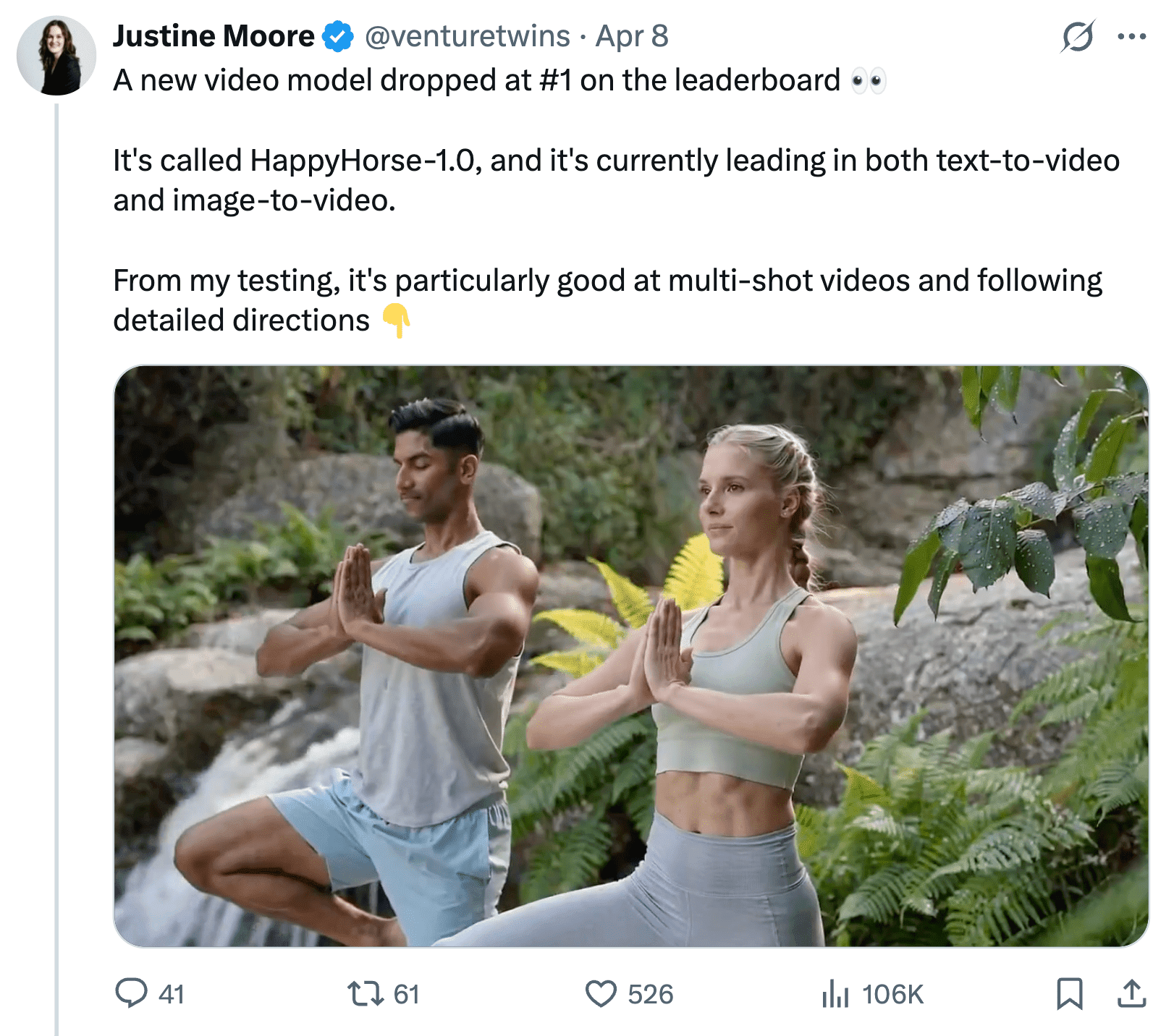
HappyHorse-1.0 is that model. It hit #1 on the Artificial Analysis Video Arena for both text-to-video and image-to-video within days of appearing. The 15B-parameter open-source model generates video and audio in a single forward pass , a fundamentally different architecture from every staged-pipeline competitor. By April 9, the team behind it was confirmed and the weights were released the same day. This article covers everything verified as of May 13, 2026: the Elo data, the architecture, the team identity, what is actually out, and the practical question every developer is asking , how should you use HappyHorse now that production API pricing is live?

Why HappyHorse-1.0 Hit #1: What the Elo Scores Actually Tell You
The Artificial Analysis Video Arena is not a self-reported benchmark. Users are shown two videos generated from the same prompt by two different models, without knowing which model made which, and they pick the one they prefer. Those votes feed an Elo rating system (the same math used in competitive chess), where a model’s score rises when users choose it and falls when they don’t.
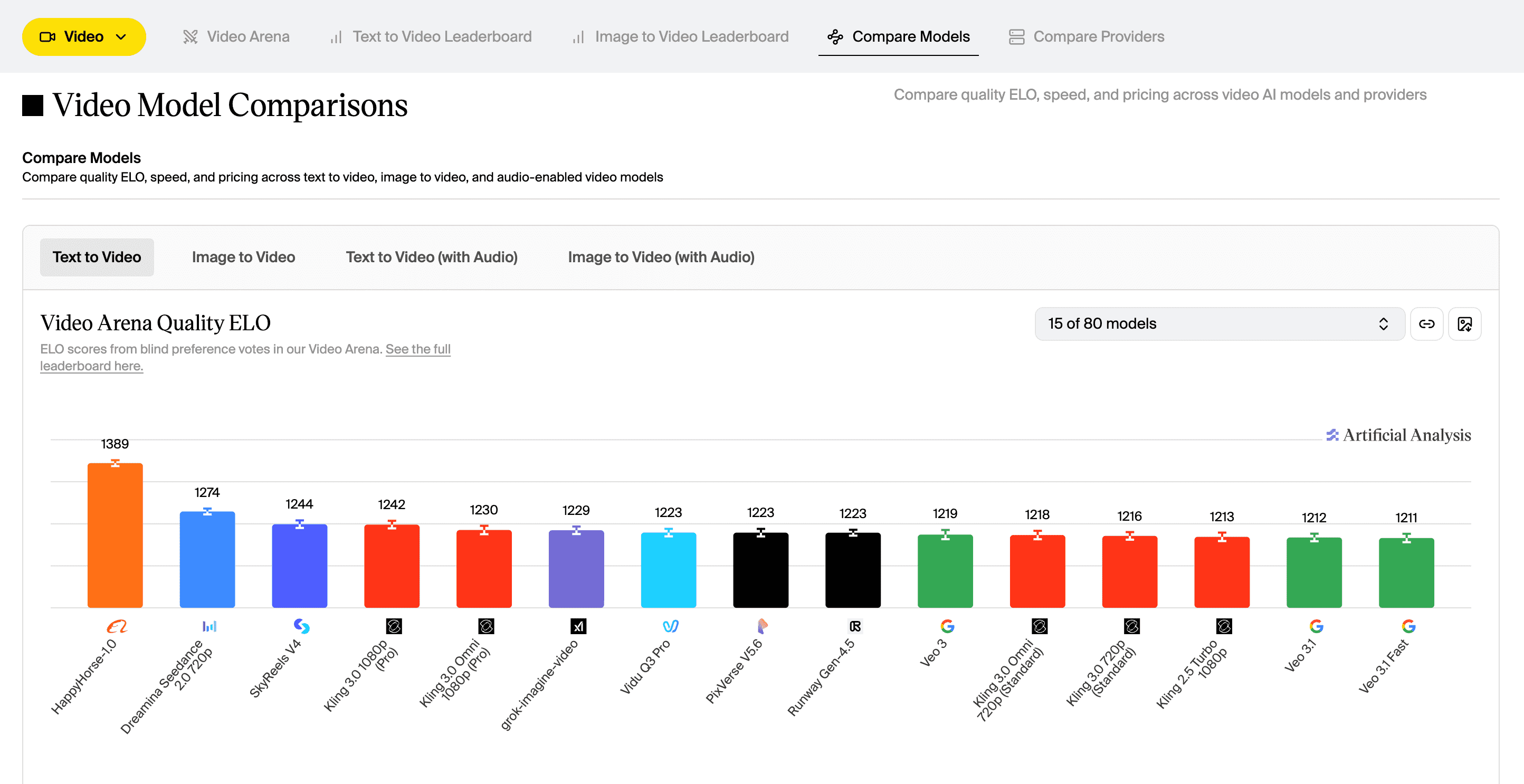
As of early April 2026, HappyHorse-1.0 ranked as follows:
| Category | Elo | Rank |
|---|---|---|
| Text-to-video (no audio) | 1,333 to 1,347 | #1 |
| Image-to-video (no audio) | 1,391 to 1,406 | #1 |
| Text-to-video (with audio) | 1,205 | #2 |
| Image-to-video (with audio) | 1,161 | #2 |
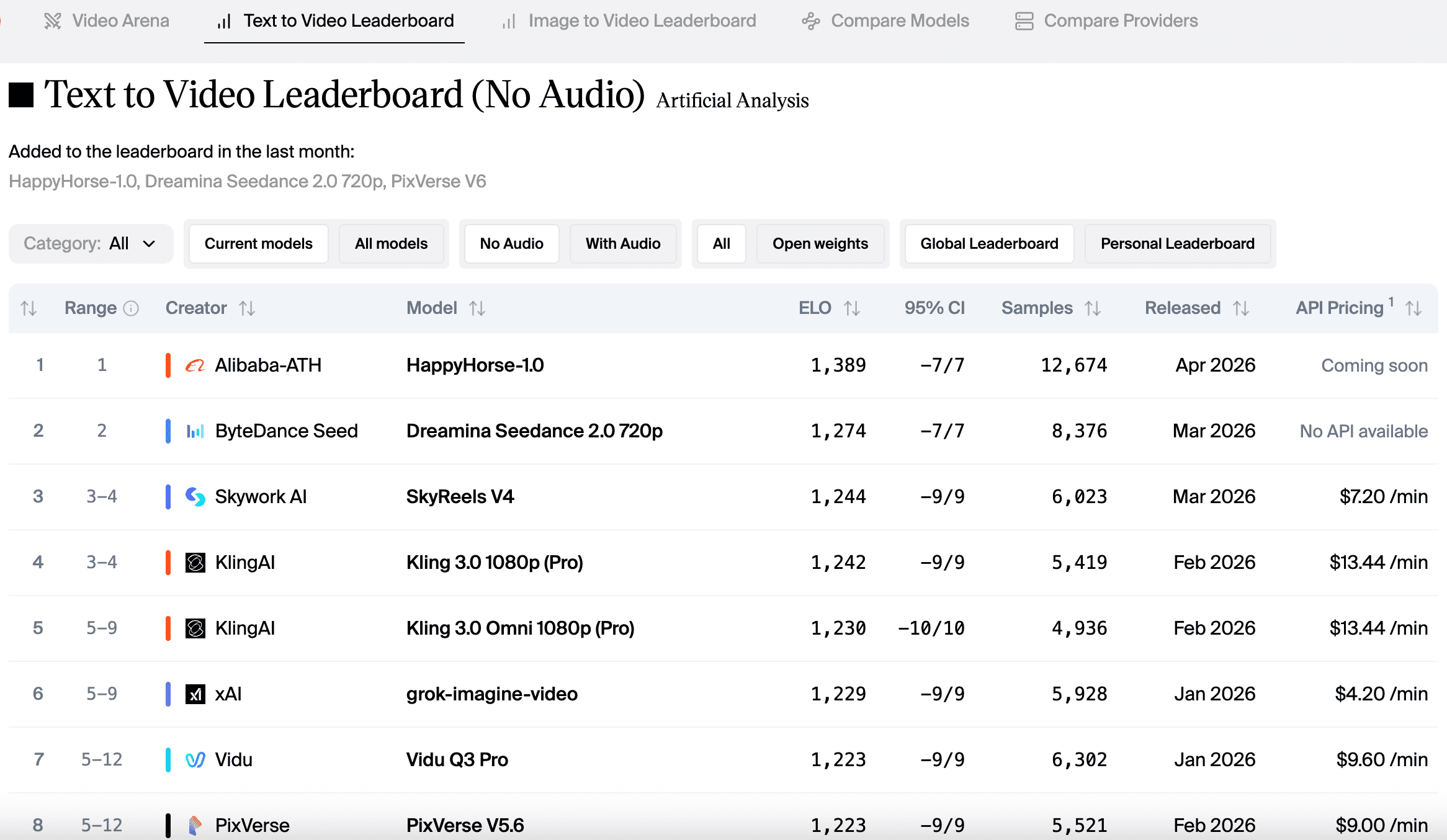
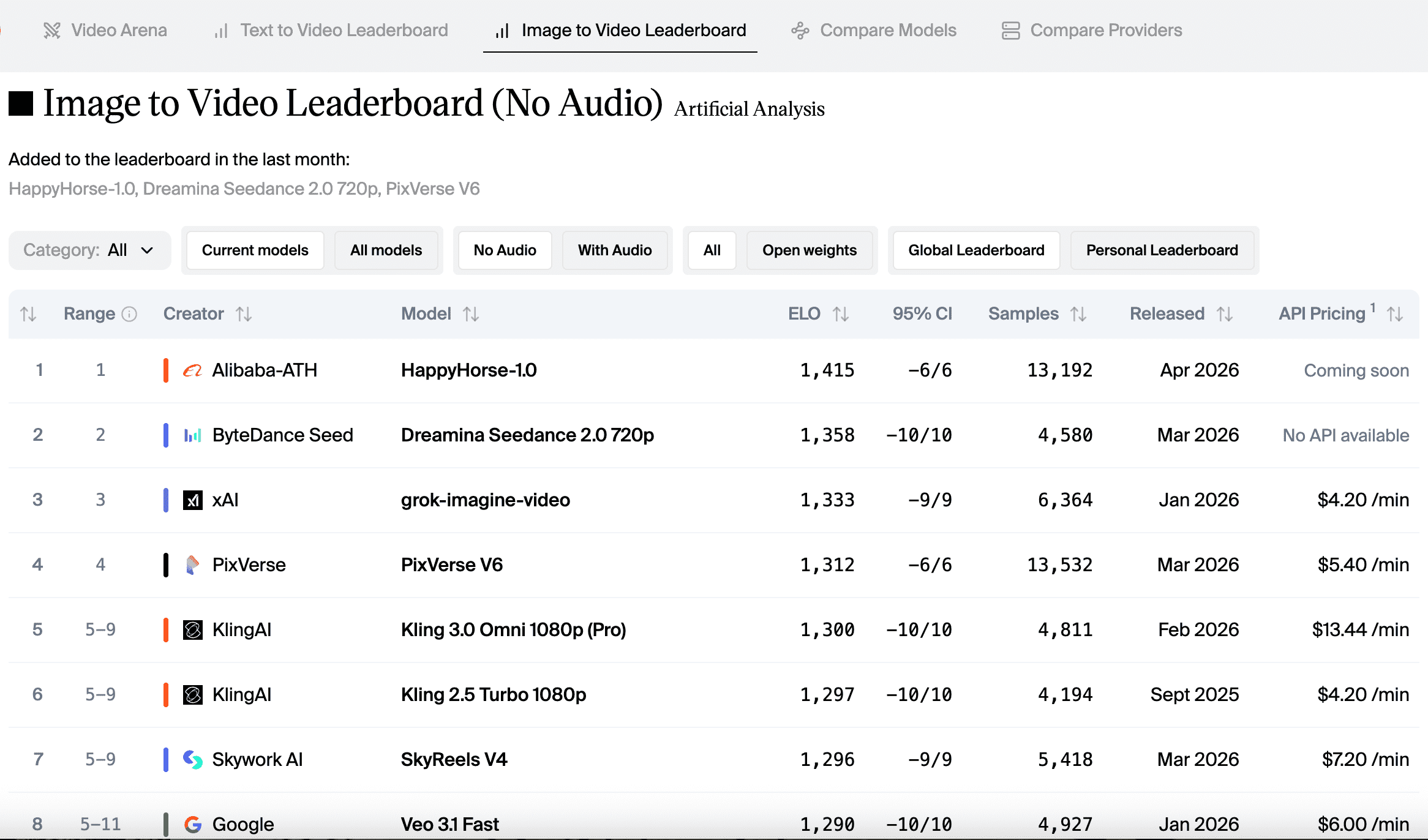
The previous #1 in text-to-video without audio was Seedance 2.0 at Elo 1,273. A 60 to 74 point gap is not statistical noise. In head-to-head matchups at that margin, the leading model wins roughly 58 to 60% of blind comparisons, which represents a consistent and meaningful difference. The image-to-video gap over Seedance 2.0 of 48 to 51 points is the widest any model has opened in that category on this leaderboard.
Two honest caveats to keep calibrated. First, newly added models carry more volatile Elo scores than established ones. Seedance 2.0 has accumulated over 7,500 vote samples in text-to-video alone, while HappyHorse’s sample count is not publicly broken out. The gap may narrow as volume grows. Second, the audio categories tell a different story: with audio included, Seedance 2.0 holds first place by 14 points in T2V and 1 point in I2V. HappyHorse’s audio generation is competitive but not dominant.
What the leaderboard data cannot tell you: whether this ranking reflects production-ready performance or optimization for the specific signals evaluators respond to. A technically sound concern raised in the Chinese AI research community (wuhu Animation, April 2026) is that models can be tuned toward the visible preference signals that blind evaluators respond to, such as facial expressiveness, audio sync, and motion sharpness, without that necessarily reflecting full-production robustness. The arena removes vendor self-reporting, but it does not eliminate the possibility of evaluation-specific tuning. Independent production testing, once weights are more widely distributed, will be the real signal.
3 Technical Reasons HappyHorse Generates Video Differently Than Competing Models
Most production AI video models use a staged pipeline: generate video frames, then align or synthesize audio in a separate pass. The timing mismatches that result are why lip sync tends to feel mechanical and ambient sound tends to feel layered on rather than native.
HappyHorse-1.0 uses a different approach. The following technical specifications come from the team’s April 8 press release and official documentation, pending broader third-party verification now that weights are publicly available.

A single 40-layer Transformer for all modalities. Text tokens, image latents, video tokens, and audio tokens are processed together in one 40-layer self-attention Transformer with no cross-attention. The architecture uses a sandwich structure: layers 1 through 4 and layers 37 through 40 apply modality-specific projections, while layers 5 through 36 share parameters across all modalities in a single sequence. Video and audio are generated jointly in one forward pass.
15 billion parameters with 8-step inference. At 15B parameters, the model is lean relative to its benchmark performance. DMD-2 distillation reduces denoising to 8 steps with no classifier-free guidance required during inference. According to the team’s reported hardware numbers (April 2026), this produces a 5-second clip at 256p in approximately 2 seconds on a single H100, and a 1080p clip in approximately 38 seconds on the same hardware.
Seven-language native lip sync. Mandarin, Cantonese, English, Japanese, Korean, German, and French are supported natively for voice generation with lip sync, within the single-pass architecture rather than a separate voice model.
Why the image-to-video score matters specifically for builders: when you provide a reference image, the model’s accuracy in following that reference (maintaining subject identity, composition, and visual coherence through motion) is what the I2V Elo captures. For product video, brand content, and any workflow starting from a specific visual asset, reference fidelity matters more than unconstrained generative quality. An I2V Elo of 1,391 to 1,406 is the highest recorded on this leaderboard as of April 2026.
Who Built HappyHorse-1.0: How the Internet Found Out and What’s Confirmed
When Artificial Analysis added the model on April 7, they described it as “pseudonymous.” No company, no team, no paper. The community investigation that followed covered multiple serious candidates before landing on an answer.
The Kuaishou theory emerged first. A technical analysis of the HappyHorse website source code surfaced the string “spaceship,” a term that overlapped with a trademark associated with a Kuaishou-linked entity. Kuaishou’s technical depth in AI video generation is well-established, and the theory had structural logic. It was not confirmed.
The daVinci-MagiHuman theory was the most technically detailed. The open-source project daVinci-MagiHuman, developed by Sand.ai and GAIR Lab (Shanghai Institute for Innovation in Computing), matched HappyHorse’s stated specs closely: same parameter count, same supported language list, similar inference speeds. A 36Kr investigation found the benchmark numbers and website structures to be nearly identical. Community members who tested daVinci-MagiHuman reported that quality did not match HappyHorse’s arena outputs, suggesting either the models are unrelated or that HappyHorse represents a substantially improved iteration. Not confirmed.
ByteDance was effectively ruled out on commercial logic. HappyHorse’s marketing directly compared outputs against Seedance 2.0 and Dreamina at every opportunity. A company attacking its own flagship video products would be an unusual strategy.
The confirmed answer, announced April 9: HappyHorse-1.0 was built by the Future Life Lab (ATH-AI Innovation Division) within Alibaba’s Taotian Group, led by Zhang Di, former Vice President of Kuaishou and the person who built Kling AI from its earliest versions.
Zhang Di’s background: Master’s degree from Shanghai Jiao Tong University in computer science. Joined Alibaba in 2010 and spent a decade as a senior technical expert leading large-scale ML infrastructure. Moved to Kuaishou in 2020 as technical lead, architecting Kling 1.0 and 2.0 (models that set a benchmark for Chinese AI video quality). Returned to Alibaba’s Taotian Group in late 2025.
The Alibaba attribution was treated as significant by financial markets. According to wuhu Animation community reporting (April 2026), Alibaba stock rose nearly 8% in trading following the disclosure.
The team describes itself as “an independent AI research collective focused on open and accessible multimodal generation technologies,” positioning that is deliberately separate from the Alibaba corporate identity, consistent with the pseudonymous launch strategy. Whether this is a permanent independent structure or an internal lab with external branding is not yet clarified in official communications.
What HappyHorse-1.0 Does Well and Where the Limits Are
Based on third-party testing by AI researchers and content creators published in April 2026, not from team-provided demo materials:
Multi-shot narrative consistency. Prompts describing scene transitions are handled with persistent character identity across cuts. Testing by X researcher @venturetwins showed that detailed, instruction-heavy prompts produced high adherence to specified camera moves, lighting conditions, and character behaviors across scene breaks, which is a capability where most current models degrade significantly.
Motion physics on non-human subjects. Bat flight sequences and animal motion tests showed physical plausibility at a level reviewers compared favorably against Seedance 2.0 outputs on equivalent prompts.
Audio-video synchronization within the single-pass architecture. Because audio is not a post-processing step, temporal drift between lip movement and speech is reduced. Reviewers consistently noted this as a distinguishing factor versus models that synthesize audio separately.
Where the model shows limits: The team’s own demo material contains visible artifacts. A flying vehicle moving underwater with no bubble effects is the most cited example across multiple reviews. In the audio categories on the Artificial Analysis leaderboard, Seedance 2.0 holds first place, suggesting that combined audio quality has not yet surpassed the current leader. The question of evaluation-specific tuning (whether leaderboard performance corresponds to production robustness) remains open until broader independent testing produces results.
Open-Source Status: What Developers Can Verify Right Now
The team’s April 9 statement: HappyHorse-1.0 is fully open-source under a commercial license. All model weights, distilled versions, super-resolution module, and inference code are released on GitHub.
This is a meaningful shift from the situation on April 8, when WaveSpeed’s original article accurately reported that both the GitHub and Hugging Face links displayed “coming soon.” The release announcement came the following day, alongside the team identity disclosure.
For independent verification, the practical checklist before attempting local deployment:
- Weights available for download (not behind a waitlist or placeholder page)
- A license file (Apache 2.0 is the clearest green light for commercial use)
- Inference code that runs without proprietary dependencies
- A model card with architecture details, limitations, and intended use
Community verification of the released weights is actively underway as of April 10, 2026. Check the official GitHub directly before drawing conclusions from any article, this one included.
Hardware requirements as stated by the team (April 2026): A single NVIDIA H100 for optimal performance, with approximately 38 seconds per 1080p clip. Community versions for consumer-grade GPUs are described as under development.
The Practical Leaderboard: Which AI Video Models Builders Can Actually Use Today
| Rank | Model | T2V Elo | API Available | Pricing |
|---|---|---|---|---|
| #1 | HappyHorse-1.0 | 1,333 to 1,347 | Yes, via API access | 720p: $0.128/s; 1080p: $0.229/s |
| #2 | Seedance 2.0 | 1,273 | Yes | Via API providers |
| #3 | SkyReels V4 | 1,245 | Yes | $7.20/min (as of April 2026) |
| #4 | Kling 3.0 1080p Pro | 1,241 | Yes | $13.44/min (as of April 2026) |
| #5 | PixVerse V6 | 1,240 | Yes | $5.40/min (as of April 2026) |
Leaderboard quality and practical usability are two different questions. HappyHorse-1.0 holds the highest Elo scores in two of four categories, and its production economics are now easier to model because API pricing is documented by resolution. The latest HappyHorse price cut moves 720p from $0.18/s to $0.128/s and 1080p from $0.30/s to $0.229/s, both billed in USD per second.
For teams building production pipelines, HappyHorse is no longer just an open-source model to watch. It is now a practical candidate when you need top-tier video quality and predictable per-second pricing. Seedance 2.0 remains strong for audio-included leaderboard categories, Kling 3.0 runs native 1080p, and SkyReels V4 remains a useful quality-to-cost reference point.
Note on third-party “HappyHorse” sites: Multiple sites (happyhorse.app, happyhorse.video, and others) are using the HappyHorse name but have not publicly confirmed they run on the HappyHorse-1.0 model that ranked on Artificial Analysis. They are separate products with their own terms and pricing. Treat them independently.
How to Integrate Top AI Video Models Without Rewriting Your Pipeline
The release pattern playing out here (leaderboard debut, open-source announcement, then API access) is becoming a predictable cycle in AI video. Wan, HunyuanVideo, and LTX-2 all followed similar trajectories. Builders who waited for each API to be available separately absorbed more switching costs than teams that abstracted the model layer.
The practical approach: build against a unified API layer that gives you access to HappyHorse, Seedance 1.5 Pro, Kling 3.0, Wan 2.6, and other production-ready video models today. When pricing, quality, or latency shifts, you change a model parameter, not your integration architecture.
Modellix provides exactly this: a unified AI media API covering video, image, and audio generation across models, with transparent per-request pricing and no separate account management per provider. HappyHorse is now available at $0.128/s for 720p and $0.229/s for 1080p, after reductions from $0.18/s and $0.30/s respectively.
Start generating video through the Modellix API , choose HappyHorse when you want the current open-source benchmark leader, or route to Seedance, Kling, Wan, and other video models from the same integration.
Modellix collection
Shortlist AI Video Models for Production
Compare text, image, and reference-led video workflows across multiple models from one production surface.
Good first tests: Seedance 2.0Wan 2.7HappyHorse 1.1
Explore the collectionHow to Test HappyHorse Before API Integration
Most readers should not start with code. Use the Modellix Playground to run one real HappyHorse job first, then move to API, Skill, or CLI only after the prompt, settings, cost, and output format are worth repeating. This keeps the guide useful for creators, product teams, and technical buyers, while developers still get a clean implementation path.
Quick start guide
Choose the right entry point for HappyHorse
Playground: Best for most readers and first-time tests. Open the HappyHorse model page and test a short prompt that reflects the motion or style you actually need: https://www.modellix.ai/models/alibaba/happyhorse-1.0-t2v.
API docs: Use this when a developer is ready to turn the validated prompt into a backend, batch, or product workflow. Start with HappyHorse request parameters and production API access: https://docs.modellix.ai/alibaba/happyhorse-1-0-t2v.
Skill: Use the Modellix Skill when an AI agent should create media from your workspace without hand-writing every request: https://docs.modellix.ai/ways-to-use/skill.
CLI: Use the CLI for repeatable terminal commands, local scripts, or scheduled generation jobs: https://docs.modellix.ai/ways-to-use/cli.
The links above are the routing layer. The walkthrough below is the practical path for the main audience: create an account, use the included credit, run one Playground job, and only then decide whether an API key is necessary.
Step 1: Create or Sign In and Use the Included $1 Credit
Create or sign in to a Modellix account before you test HappyHorse video generation. New users can use the included $1 credit to validate model behavior, prompt quality, output download, and request logging without committing to a full integration.
Step 2: Open the Model Page and Run One Prompt
After login, use the dashboard shortcuts or the Modellix model catalog to open HappyHorse 1.0 T2V model page. For video models, start with a short clip, then check aspect ratio, duration, resolution, motion quality, and whether the output is worth repeating. This step is the fastest way to learn whether the model fits before you read more code.
Step 3: Optimize the Prompt and Review the Output
Before you automate anything, improve the prompt and inspect one real output. The example below uses Vidu Q3 Mix R2V, but the same Playground pattern applies across Modellix model pages: write the prompt, use prompt enhancement when the brief is too thin, run the job, and review the generated media before creating an API workflow.

After the run finishes, check whether the result matches the prompt, motion, framing, and output format you need. A real preview is the conversion point: if the result works, move to API key, Skill, or CLI; if it does not, iterate in Playground before spending engineering time.

Step 4: Create an API Key Only When the Test Needs to Repeat
Stay in Playground for one-off exploration. Create an API key when a backend service, agent, batch script, or CLI workflow needs to repeat the same prompt pattern. This keeps the mainstream testing flow simple while giving developers a clean handoff point.
Step 5: Check Logs and Save the Result Before Scaling
Before scaling from one manual run to repeated API, Skill, or CLI usage, review request history. Logs confirm the model slug, API key name, task status, request time, and result retention window, which makes the workflow easier to debug after it leaves Playground.
Try HappyHorse Next
The practical next step is to run one real job from the official site, not to copy a complex code sample too early. Start from the Modellix console, open the HappyHorse 1.0 T2V model page, and move to API, Skill, or CLI only after the output is good enough to repeat.
Verify the benchmark leader with your own prompt
Open the official HappyHorse model page and run one clip with the included credit. Judge the output on your own brief before you move the model into an automated workflow.
Frequently Asked Questions About HappyHorse-1.0 (May 2026)
Who built HappyHorse-1.0, and when was it confirmed? The Future Life Lab (ATH-AI Innovation Division) within Alibaba’s Taotian Group, led by Zhang Di (former VP of Kuaishou and technical architect of Kling AI). Team identity was confirmed on April 9, 2026.
What are the current Elo scores on Artificial Analysis? T2V (no audio): 1,333 to 1,347, ranked #1. I2V (no audio): 1,391 to 1,406, ranked #1. T2V (with audio): 1,205, ranked #2. I2V (with audio): 1,161, ranked #2. These numbers will shift as vote volume grows. Check the live leaderboard for current standings.
Is HappyHorse-1.0 actually open-source with a commercial license? The team announced full open-source release on April 9, including model weights, distilled versions, super-resolution module, and inference code. Community verification is in progress. Verify the current status on the official GitHub before deployment.
Is there a public production API? Yes. As of May 13, 2026, HappyHorse can be used through production API access with resolution-based pricing: $0.128/s for 720p and $0.229/s for 1080p.
How does it compare to Seedance 2.0 in practical terms? In blind tests without audio, HappyHorse leads Seedance 2.0 by 60 to 74 Elo points in T2V and 48 to 51 points in I2V. With audio, Seedance 2.0 leads by 14 points in T2V and 1 point in I2V. Now that HappyHorse has API access and lower per-second pricing, the decision depends on whether your workflow values no-audio visual quality, audio-included performance, or specific latency and resolution requirements.
What hardware is needed to run it locally? A single NVIDIA H100 for optimal performance (approximately 38 seconds per 1080p clip, as reported by the team in April 2026). Consumer GPU community versions are in development.
Is HappyHorse-1.0 related to Alibaba’s Wan 2.7? No confirmed connection. Both are Alibaba-ecosystem projects but appear to be separate model lines with different architectures. The HappyHorse team’s stated architecture does not match publicly known Wan architecture.
What is the fastest way to access top AI video models via API today? Modellix provides a unified API covering HappyHorse, Seedance 1.5 Pro, Kling 3.0, Wan 2.6, and other leading models with a single integration. HappyHorse currently costs $0.128/s for 720p and $0.229/s for 1080p.
Published April 10, 2026. Updated May 13, 2026 with HappyHorse API availability and reduced pricing. Leaderboard data sourced from Artificial Analysis Video Arena. Team attribution sourced from official team press release (April 8 to 9, 2026) and wuhu Animation community reporting (April 9, 2026). Pricing data current as of May 13, 2026.


